As a teacher with students in multiple Brightspace courses, I was looking for a dashboard to show which students have unsubmitted assignments. While Brightspace does have an API available, I decided that it wasn't going to work for a few reasons. There are also commercial (non-free) plugins that can do most of what I was looking for, but this was a good opportunity to explore scraping of content from dynamic web pages with Python.
You may be familiar with the Python Requests and Beautiful Soup libraries, which are great, but since Brightspace is requiring a Microsoft login I needed to go with Selenium. Selenium is designed for automating web browser interactions, which means we can use it to log in to a site and scrape pages.
While Selenium can be installed and run locally, it also works in a Colab notebook:
!apt update !apt install chromium-chromedriver !pip install selenium from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By options = webdriver.ChromeOptions() options.add_argument('--headless') options.add_argument('--no-sandbox') browser = webdriver.Chrome(options=options)
Once that is set up, we need to log in to our Brightspace server:
email = 'teacher@example.com' base_url = 'https://example.brightspace.com' import getpass # so you don't show your password in the sourcecode password = getpass.getpass() email_field = (By.ID, 'i0116') password_field = (By.ID, 'i0118') next_button = (By.ID, 'idSIButton9') browser.get(base_url) WebDriverWait(browser,10).until(EC.element_to_be_clickable(email_field)).send_keys(email) WebDriverWait(browser,10).until(EC.element_to_be_clickable(next_button)).click() WebDriverWait(browser,10).until(EC.element_to_be_clickable(password_field)).send_keys(password) WebDriverWait(browser,10).until(EC.element_to_be_clickable(next_button)).click() WebDriverWait(browser,10).until(EC.element_to_be_clickable(next_button)).click()
From there it's a matter of scraping the course progress pages as we loop through the course IDs and student IDs. I may update this post later with an automated way to scrape these IDs, but for now we need to look them up on Brightspace and code them in:
import pandas as pd df = pd.Series(students).to_frame('ID') for course in courses: course_id = courses[course] submissions = [] for student in students: student_id = students[student] url = base_url+'/d2l/le/classlist/userprogress/'+str(student_id)+'/'+str(course_id)+'/Assignments/Details' browser.get(url) WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "span[class^='d2l-textblock']"))) elements = browser.find_elements_by_css_selector("span[class^='d2l-textblock']") #elements = browser.find_element(by=) # because the other thing is deprecated I guess #submitted = elements[13].text[1:-1] # to get a fraction submitted = elements[13].text[1:-1].split('/')[0] # to get just the numerator submissions.append(submitted) df[course] = submissions df.to_csv('student-submissions.csv') df
This will give us a Pandas DataFrame (and a CSV file) with information about how many assignments each student has submitted in each course. We can manipulate this a bit to create some visualizations, but perhaps that's a post for later. For now, here's part of a chart that we could generate:
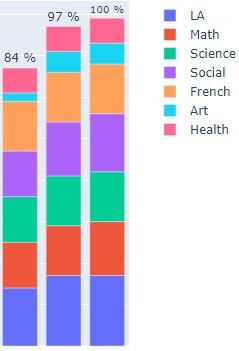
Let me know if you try this or if you come across anything that should be corrected.